Catalogue
1.4. > 预测框的获得 1.5. > 寻找最佳的anchor box 1.6. > LOSS值的计算 1.6.1. 在loss值的计算过程中预测框被分为三类: 1.7. > 图片预测
- 1.6.1.1. 正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出 [公式] );类别标签对应类别为1,其余为0;置信度标签为1。
- 1.6.1.2. 忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。(存在意义:由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。)
- 1.6.1.3. 负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
YOLOv3 model.py代码的简单分析注解
> 准备
1 | from functools import wraps |
> YOLO网络
首先要通过特征提取网络对输入的输入图像提取特征,得到不同尺寸的特征图
### 代码
1 | #@wraps在此处的作用是为了使DarknetConv2D.__name__和DarknetConv2D.__doc__与Conv2D__name__和Conv2D.__doc__相同。 |
流程图
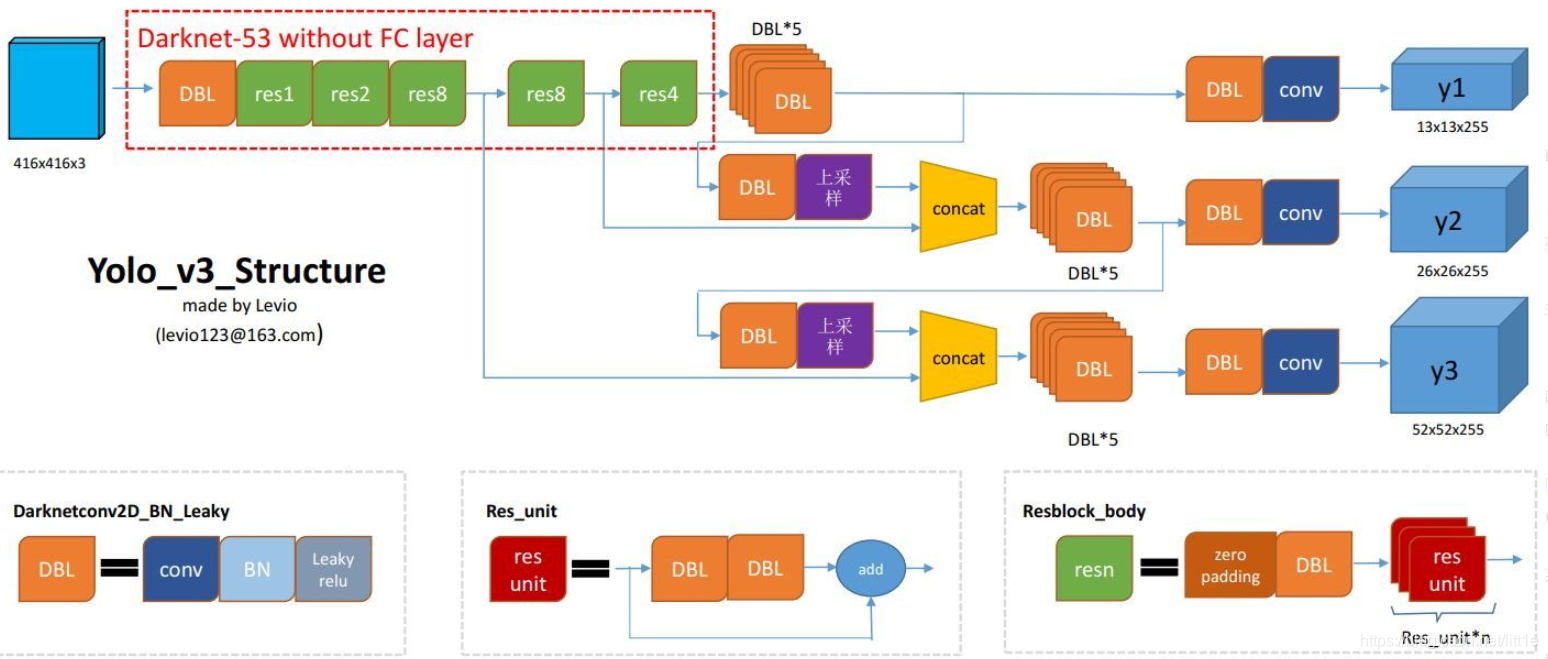

整个yolov3网络共252层,组成如下:

> tiny_yolo_body
轻量版的YOLO,有速度快,占内存少等的优点,视情况选择使用。
1 | def tiny_yolo_body(inputs, num_anchors, num_classes): |
> 预测框的获得
1 | #将预测值的每个特征层调成真实值 |
求得bx,by,bw,bh的公式
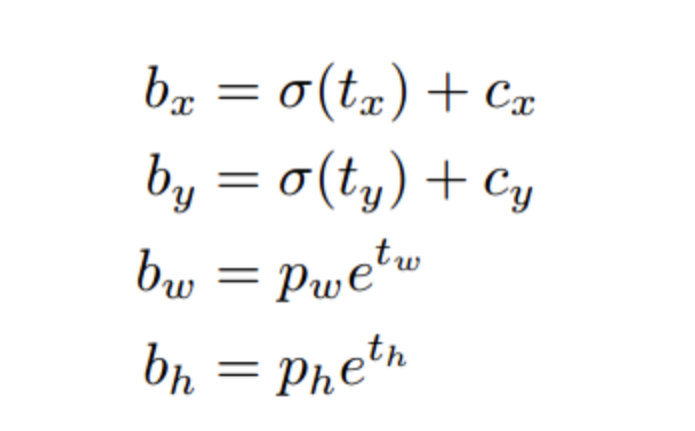
对yolo_correct_boxes部分代码的补充说明

> 寻找最佳的anchor box
1 | def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes): |
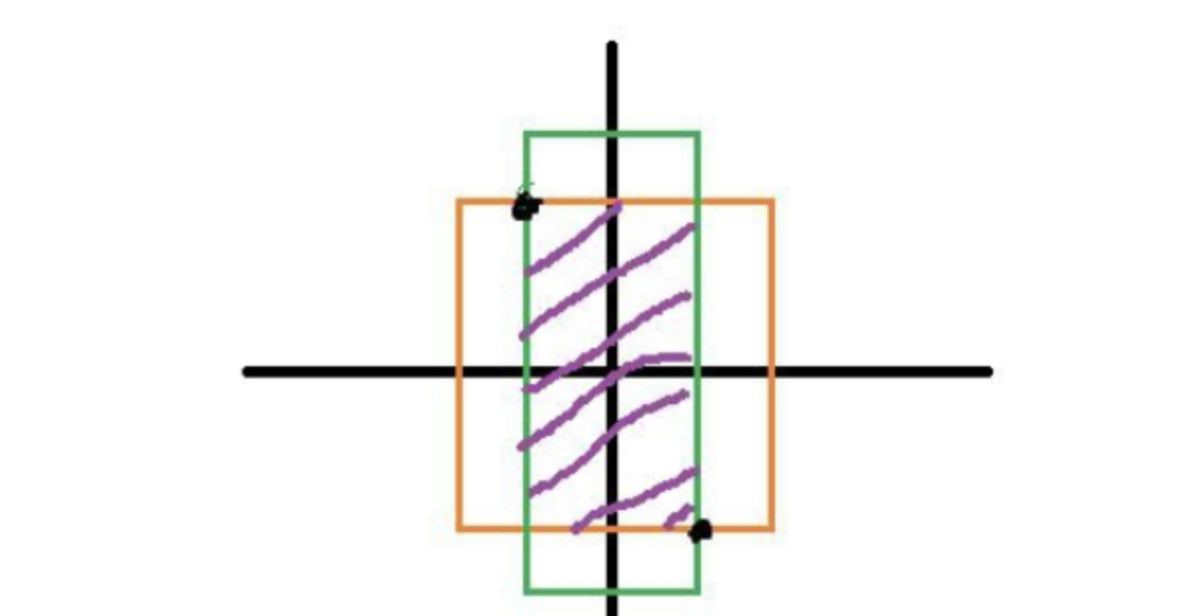
preprocess_true_boxes中涉及到的anchor box和ground truth经过/2和取反等处理后,其相对关系应大概如图所示:
> LOSS值的计算
(1)计算xy(物体中心坐标)的损失:xyloss=bool*(2-areaPred)*bce
(2)计算wh(anchor长宽回归值)的损失:whloss=bool*(2-areaPred)*bce
(3)计算置信度的损失:whloss=bool*(2-areaPred)*bce
(4)计算类别损失:置信度乘上多分类的交叉熵
1 | #定义一个iou函数 |
在loss值的计算过程中预测框被分为三类:
正例:任取一个ground truth,与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出 [公式] );类别标签对应类别为1,其余为0;置信度标签为1。
忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生任何loss。(存在意义:由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。)
负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
> 图片预测
1 | def yolo_eval(yolo_outputs, |